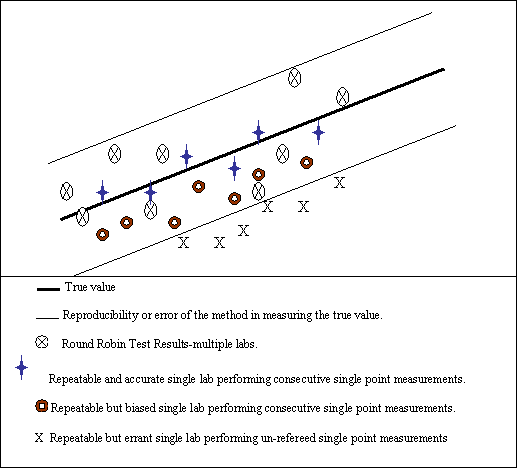
Accuracy – the ability of any test method, lab analysis, or analyzer, to yield the true value of the sample as a result of the measurement. That is, the result of the measurement gives the true value within the error of the measurement. The accuracy of any method is best determined by round-robin testing of that method.
Reproducibility – the determination of the spread around the true value. Determined by multiple measurements of the same samples at multiple sites (round-robin testing). It is the true error of the method.
Repeatability – the measurement of the spread around a test result from a single analyst and/or single analyzer at the same site on the same sample. However, this does not mean that the result is accurate (produces the true value).
Precision – the level to which any measurement can be accurate. That is, 46 or 46.259.
Bias – a definite offset from the true value. Consecutive single point measurements can be biased.
Model Definitions
Global Model: Any chemometric based prediction that incorporates lab analyses and samples from multiple locations on multiple streams, multiple processes, and multiple stream sources (i.e. crudes). By definition then, the prediction is accurate (predicting the true value) to within reproducibility. In order to compare a global model prediction to any single point lab measurement, the lab must first validate that the lab can meet the reproducibility requirements of the method, or ascertain it’s actual reproducibility by as described in ASTM D3764. Once the lab measurements are validated, single point lab measurement comparisons to the chemometric prediction should be within reproducibility limits. Global models are less prone to bias errors and drift.
Model Training: The process of enabling a global model to statistically recognize (i.e. f-test, mahalanobis distance, etc) the spectral results of a specific analyzer at a specific location. Requires no extensive lab sampling and analyses or exorbitant input of local unit and process specific spectral files to the model.
Local Models and Localization: Local models are built on data from a specific process unit, in a specific location, usually incorporating only lab analyses from the on-site laboratory. This effectively makes the model an on-line duplicate of the on-site laboratory and therefore subject to bias. Further, if a model is localized too much, it can be prone to drift (moving away from the true value) and/or fail to predict outside of the model space when the process changes or experiences an upset.
NMR Reproducibility: The limits of the differences between a valid, single point lab measurement and an NMR predicted result. This value is determined by the primary method and range of samples that the model is built on.
NMR Repeatability: The limits of the differences between successive predictions on a blocked in sample in the NMR under defined conditions. This value is determined bythe primary method and range of samples that the model is built on.
NMR Model and Application Strategies
NMR models based predictions are based on two types of applications: Process Control or Product Certification.
Process Control: Feed Forward and/or Feedback
- NMR models cover a wider sample range.
- Very Robust: continue to accurately predict over wide process ranges.
- Reproducibility differences between the NMR prediction and any single point lab measurement will be slightly higher.
Product Certification: i.e. Blending
- NMR model ranges are narrowed and confined with respect to the product (i.e. gasoline and blend components only)
- NMR validation set at product certification levels.
- Models are not as robust. That is, a gasoline blending model will not predict a diesel fuel as accurately as a more broad based model.